Continuando a serie de posts sobre como fazer um sistema operacional. O código desta parte também já esta no repositório.
Nesse post vamos finalmente ter alguma ação, vamos codificar algo. E mais interessante ainda, em ASM.
O que ser assembly?

A linguagem Assembly(vamos chamar simplesmente de ASM) é uma linguagem de baixo nível, que quer dizer que tem uma abstração quase inexistente da linguagem de maquina.
Devido a sua pouca abstração, o ASM normalmente é extremamente não portável. Isso quer dizer que, o ASM é extremamente atrelado a ISA e ao SO para a qual esta se programando.
Existem diversas variações de ASM, e cada um tem suas características. Uns podem ser mais portáveis, ter uma linguagem de mais alto nível e/ou outras funcionalidades.
O paradigma de programação em ASM normalmente é bem linear e não estruturado. E a forma mais básica da linguagem é através de mnemônicos de instruções, se repetindo a cada linha do programa, imitando a linguagem de maquina.
Como ASM é altamente ligado a ISA, normalmente vamos precisar de uma implementação diferente para cada ISA. De vez em quando podemos contornar isso, mas no nosso kernel por enquanto estamos implementando para i386 apenas, então não vamos nos preocupar tanto com isso.
Conhecer totalmente ASM não é obrigatório, mas entender um pouco do que vai ser codificado mais a frente é necessário. Não vamos codificar muito em ASM, apenas o que realmente for preciso.
Porque precisamos do ASM?
Infelizmente, não é possível escrever totalmente o kernel em C/C++. Mas porque, você se pergunta?
C/C++ não fornece funcionalidades para garantir que o cabeçalho do mboot fique no começo do kernel. Se você declara dados em C/C++, esses dados ficam na secção “.data”, “.rodata” e/ou outras(como foi abordado em posts passados). Teoricamente, você pode escrever em ASM diretamente em C/C++, mas isso é conversa para o futuro.
Quando você executa uma função em C/C++, você teoricamente já esta usando a pilha, então não da para indicar uma função de C/C++ como ponto de inicio do kernel sem usar uma pilha. Não temos como garantir com C/C++ que essa pilha previamente configurada esteja usando uma área de memoria valida. Isso pode fazer com que o código sobrescreva uma área de memoria importante ou até acesse uma área de memoria mapeada para alguma outra finalidade, podendo causar erros.
Não podemos garantir que funções em C/C++ sejam iniciadas sem alterar registradores específicos. Então se indicarmos uma função de C/C++ como ponto de inicio do kernel, quando ela for iniciada vamos perder informações de alguns registradores. Isso não tem nenhuma forma de contornar(que eu saiba, acho que rótulos do C/C++ não podem garantir isso…), e isso vai se tornar mais evidente quando estiver programando o IDT, GDT e etc…
Se existir formas de fazer isso apenas em C/C++ padrão/portável(ou o mais possível…), por favor me avisem :p.
Implementando nossa rotina de inicialização em ASM
Vamos criar o arquivo “/minios/kernel/arch/i386/pc/start.s“. Nessa pasta porque é dependente da ISA que estamos usando(i386 no caso, só para separar).
Nesse arquivo temos algo parecido com:
.section .mboot
/* Multi Boot header */
.set MBOOT_PAGE_ALIGN, 1<<0
.set MBOOT_MEM_INFO, 1<<span id="mce_SELREST_start" style="overflow:hidden;line-height:0;"></span><1
.set MBOOT_HEADER_MAGIC, 0x1BADB002
.set MBOOT_HEADER_FLAGS, MBOOT_PAGE_ALIGN | MBOOT_MEM_INFO
.set MBOOT_HEADER_CHECKSUM, -(MBOOT_HEADER_MAGIC + MBOOT_HEADER_FLAGS)
.globl mboot
.globl start
.align 4
mboot:
.long MBOOT_HEADER_MAGIC
.long MBOOT_HEADER_FLAGS
.long MBOOT_HEADER_CHECKSUM
.long mboot
.long code
.long data_end
.long bss_end
.long start
.section .text
initial_stack:
.globl initial_stack
.zero 4
multiboot_magic:
.globl multiboot_magic
.zero 4
multiboot_addr:
.globl multiboot_addr
.zero 4
start:
cli
movl %eax, multiboot_magic
movl %ebx, multiboot_addr
mov $stack_top, %esp
movl %esp, initial_stack
.hang:
hlt
jmp .hang
/* Create stack on bss section */
.section .bss
.align 16
stack_bottom:
.skip 16384 # 16 KiB
stack_top:
Vamos agora a uma explicação mais detalhada. Vamos focar em pontos importantes mais a frente.
.section .mboot
Na primeira linha, com o section garantimos que essa secção vai ficar em .mboot, que reservamos para o começo do kernel no linker, como explicado no post anterior.
.set MBOOT_PAGE_ALIGN, 1<<0
.set MBOOT_MEM_INFO, 1<<1
.set MBOOT_HEADER_MAGIC, 0x1BADB002
.set MBOOT_HEADER_FLAGS, MBOOT_PAGE_ALIGN | MBOOT_MEM_INFO
.set MBOOT_HEADER_CHECKSUM, -(MBOOT_HEADER_MAGIC + MBOOT_HEADER_FLAGS)
Algumas definições do Multi Boot. Basicamente o numero magico que identifica o cabeçalho e algumas informações que vamos passar para o gerenciador de boot.
Vamos utilizar apenas opções básica, então isso já resolve. Para entender melhor o valor de cada campo e outras opções, vocês podem consultar a pagina da GNU com todas as informações.
.align 4
mboot:
.long MBOOT_HEADER_MAGIC
.long MBOOT_HEADER_FLAGS
.long MBOOT_HEADER_CHECKSUM
.long mboot
.long code
.long data_end
.long bss_end
.long start
Esse é o cabeçalho binário do Multi Boot propriamente dito, que devemos manter no começo do kernel para que o gerenciador de boot consiga as informações necessárias e identifique o kernel como inicializável.
Perceba que é necessário que esses bytes sejam alinhados em 4, como especificado pelo padrão.
Os últimos 5 inteiros são exatamente os endereços de memoria que marcamos no linker: O endereço do cabeçalho, o endereço onde se inicia o código que vamos copiar para a memoria, o endereço até onde vamos carregar para a memoria, o endereço final da área BSS(essa área vai ser preenchida com zeros pelo gerenciador de boot, de acordo com o padrão) e o endereço de onde o gerenciador de boot vai começar a executar o kernel!
Esses últimos 5 inteiros são importante, mas é bom ressaltar que não vamos usar e eles estão ali apenas por compatibilidade. O formato do binário do kernel que vamos usar é ELF(que o mboot já sabe interpretar o cabeçalho com essas informações), então todas essas informações já estão no kernel(além de contar com outras vantagens, como um kernel menor). Se você não colocar no cabeçalho especificamente para usar essas informações(colocando 1 no bit 16 em MBOOT_HEADER_FLAGS), ele já vai carregar elas do cabeçalho do padrão ELF. Você deve estar se perguntando porque essas informações vão ficar ai? Bom, caso no futuro eu mude de formato, fica ai a opção(acho que alguns sistemas podem não ter suporte a ELF…). Também não estou certo se todos os compiladores podem gerar executáveis no formato ELF.
.section .text
initial_stack:
.globl initial_stack
.zero 4
multiboot_magic:
.globl multiboot_magic
.zero 4
multiboot_addr:
.globl multiboot_addr
.zero 4
Apenas definindo algumas variáveis globais em ASM e preenchendo com zeros. Essas variáveis não precisam ser definidas aqui, poderiam ser definidas em C/C++, acho. Provavelmente vamos remover elas quando os códigos em C/C++ começarem a aparecer.
Vamos falar da função de cada uma dessas variáveis quando atribuirmos os valores a elas mais a frente.
start:
cli
FINALMENTE!!11!1
Aqui é o rotulo/endereço de onde o seu kernel vai começar a executar depois que o gerenciador de boot fizer todo o trabalho duro. Esse rotulo vai ser tipo um “main()” do ASM. Apesar de ser difícil programar em ASM, você poderia começar a fazer sua baguncinha por aqui…..
Mas em outro dia, porque primeiramente temos que desabilitar as interrupções com a instrução cli. Porque executamos essa instrução logo? Porque, o computador esta com uma tabela de interrupções que foi configurada pelo gerenciador de boot e outras, que podem fazer comportamentos inesperados(na verdade, acho que o gerenciador de boot já desabilita, mas no futuro vamos fazer isso de novo quando for desativar o kernel).
No futuro, podemos mover essa instrução para uma função em C/C++ para ficar mais organizado, mas por enquanto estamos usando apenas ASM.
movl %eax, multiboot_magic
movl %ebx, multiboot_addr
mov $stack_top, %esp
movl %esp, initial_stack
Aqui, fazemos apenas algumas atribuições, mas elas são importantes. Muito tem a ver com o porque precisamos usar ASM no lugar de C/C++ na inicialização, como discutimos antes.
Primeiro, precisamos do conteúdo do registrador EAX, que copiamos para a área de memoria/variável chamada multiboot_magic. Porque? O gerenciador de boot vai colocar nesse registrador um numero magico(2badb002), que identifica que o kernel deu boot corretamente por um gerenciador compatível com mboot versão 1.
Segundo, precisamos do conteúdo do registrador EBX, que copiamos para a área de memoria/variável chamada multiboot_addr. Porque? Ele contem o endereço do cabeçalho do mboot, para que o kernel possa extrair informações extras que o gerenciador de boot possa passar. Na verdade não vamos usar isso, mas não custa nada armazenar.
E, para finalizar, deixamos de usar a pilha que estamos usando atualmente(que é de uma área de memoria que o gerenciador de boot usou) para utilizar uma área de memoria segura indicada pelo rotulo stack_top. Para quem não sabe, o registrador ESP indica onde esta a pilha, caso você não entenda como isso funciona, apenas assuma que isso é necessário. É necessário usar uma área de memoria valida e que possa crescer, por isso vamos alocar essa memoria na secção BSS.
No caso, essa são as únicas operações que precisamos fazer em ASM por agora. Se colocássemos uma função em C/C++ no lugar do código em ASM, o C/C++ iria usar essa pilha que o gerenciador de boot indicou anteriormente e adicionalmente provavelmente iriamos perder os conteúdos dos registradores EAX e EBX, porque o código de inicialização da função de C/C++ usaria esses registradores.
.hang:
hlt
jmp .hang
Aqui é o final do programa. Futuramente, vamos passar essa parte do código para C/C++ também.
Porque precisamos desse código? Basicamente, hlt para e espera pela próxima interrupção que o computador vai receber. Se por algum motivo alguma interrupção acontecer(não era para acontecer, mas pode), vamos executar hlt de novo, até que o computador pare de vez.
Basicamente, um loop infinito executando a instrução para parar.
.section .bss
.align 16
stack_bottom:
.skip 16384 # 16 KiB
stack_top:
Dentro da secção BSS, reservamos 16384(vulgo, 16KiB) de memoria alinhada a 16 e marcamos o começo e o final dessa área para ser a nossa pilha.
A secção BSS é a área de memoria que definimos para essas finalidades. Mas, porque precisamos alinhar? Porque o x86 diz que precisamos(tá, tem motivos para isso, mas como você é obrigado não tem opção).
Lembra que alguns passos atrás falamos sobre a pilha? Lá usamos essa área de memoria que reservamos aqui, simples assim.
Não precisamos nos preocupar com a ordem, apenas precisamos colocar os dados nas secções corretas. Isso é valido para a pilha ficar na BSS, quanto qualquer outro código que usamos mais a cima ou depois.
Executando
Agora podemos executar o código depois de compilado usando o qemu. Precisamos de dois requerimentos para isso:
- O emulador de i386 ou parecido
- Um GCC que produza executáveis para i386
Você pode fazer um toolchain para a arquitetura que você vai usar, que envolve produzir todo um ambiente de compilação para a arquitetura especifica. Mas, i386 é muito comum, então pode ser que você tenha o compilador já no seu sistema. Enfim, não vou entrar em detalhes disso, porque não vai ser meu foco.
Considerando que tudo esta certo, você poderia compilar e executar o SO assim:
git clone -b 'V00.05' https://bitbucket.org/psycho_mantys/minios
mkdir minios/build
cd minios/build
cmake ..
make
../tools/boot_qemu.sh
Pronto! Claro, esses comandos são para usar um ambiente linux/unix e usando linha de comando. No seu ambiente, você pode utilizar qualquer outra ferramenta gráfica ou procedimento que achar mais interessante para baixar, compilar e rodar o sistema operacional.
Analisando a execução
No meu ambiente(e espero que seja parecido em outros também), depois de executar o kernel usando o qemu, vamos ter uma imagem mais ou menos assim:

Certo, o que mudou você se pergunta? Exatamente, nada :/.
Apesar de todo o trabalho que fizemos até agora, praticamente o nosso kernel não faz nada(nenhuma alteração visual na tela, ainda vamos chegar lá). Poderíamos executar algum código no rotulo “start” além do que já colocamos lá, mas teríamos que programar em ASM, que não é nosso escopo por agora.
Como vamos saber que estamos fazendo tudo certo então? Basicamente, de duas formas.
A primeira é olhando a saída do comando “/tools/boot_qemu.sh” que estamos usando para executar o kernel. Nesse script codificamos para que ele informe o conteúdo dos registradores depois de um tempo, que é quando o kernel já deve estar parado no loop infinito. Como nosso kernel esta em conformidade com o padrão mboot versão 1, então, no registrador EAX o gerenciador de boot deve colocar o valor magico(um magic number) “2badb002” para garantir que o kernel foi iniciado por um gerenciador de boot compatível(você poderia atribuir algum valor magico a esse registrador também e verificado depois).
Analisando a saída, podemos ver que isso é verdade:
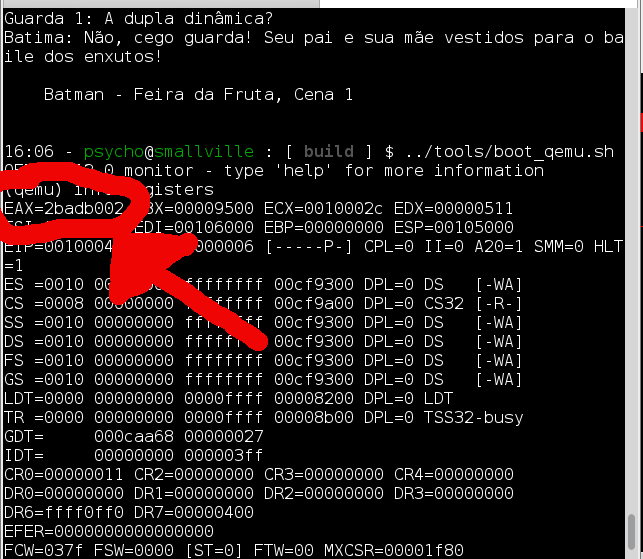
Um problema que pode acontecer é do seu kernel não ter ou não estar com o cabeçalho do mboot certo. Se você estiver implementando da forma correta no “start.s”(na secção correta e os dados certo), você também pode verificar no arquivo binário do kernel se o cabeçalho esta certo e no lugar correto. Como podemos fazer isso? Você pode abrir o arquivo binário(usando um visualizador de binário com o comando hexdump ou até qualquer editor de sua escolha) e verificar se os dados estão no começo. Também tem como verificar isso usando o grub-file. Para uma forma mais conveniente, eu vou usar o comando “objdump” e verificar se a secção esta em um offset do arquivo perto do começo:

Como podemos ver, a secção esta localizada pelo inicio do arquivo, o que é bom.
Recapitulando o processo todo
Agora que temos algo executando, creio que seja importante recapitular o processo todo de inicialização passo a passo de forma direta:
- O gerenciador de boot procura no arquivo binário do kernel o cabeçalho do mboot
- Gerenciador de boot carrega para a memoria o conteúdo do kernel indicado no endereço no quinto campo do cabeçalho até o endereço do final(que é indicado no sexto campo) ou usa o valores no cabeçalho ELF
- Gerenciador de boot preenche com zeros a memoria da BSS até o endereço de memoria indicado no sétimo campo do cabeçalho ou o indicado no cabeçalho ELF
- Gerenciador de boot coloca o numero magico no registrador EAX para indicar que o kernel foi inicializado pelo padrão do mboot versão 1
- Com todo o ambiente configurado, o gerenciador de boot passa o fluxo de execução para o endereço que é indicado no oitavo campo cabeçalho ou o indicado no cabeçalho ELF
- Executamos o código do kernel
Uma boa leitura sobre o multiboot versão 1 é o manual da GNU. Apesar de não explicar direito o processo de compilação e muita coisa ser implementada em ASM e sem explicação, é uma consulta bem explicativa no mínimo para o processo de boot.
Palavras finais
O foco dessa parte não é ensinar ASM, mas é um conhecimento interessante de se ter, pelo menos o básico.
Em vários pontos em fiquei tentado a implementar o mboot versão 2. Apesar de serem parecidos, não tem muito necessidade dentro do que estou fazendo. Fica mais fácil fazer com o padrão 1 porque já sei o que fazer mesmo. Talvez no futuro eu reveja isso.
Algumas coisas eu estou relembrando, e uma parte do processo esta sendo refazer algumas coisas. Caso algo seja estranho ou pareça errado, seria bom que alguém me avise.
Uma boa coisa é se alguém souber melhores formas de fazer alguma coisa, é bom me avisar pelos comentários, ou dar sugestões para melhorar. Não existe uma melhor forma única de fazer tudo, mas estamos tentando utilizar de todas as melhores pelo menos.
Não sei se a didática esta boa, sinto que estou sendo um pouco prolixo de vez em quando, mas acho que é bom em alguns momentos. E como estou implementando enquanto vou postando, não sei ainda a melhor maneira.
Enfim, qualquer ideia falem ai.






